
ChemMapBaseとは

創薬・研究開発に不可欠な化合物探索・選定の業務効率を、飛躍的に向上させるソリューションです。
1億件を超えるような大量の化合物データに対しても、独自の検索エンジンとデータベースにより、高度な検索を超高速に実現。
お客様のニーズに合わせた付加データの取り込みや連携にも柔軟に対応できるカスタマイズ性を備えています。
ChemMapBaseの特長
1. PubChemやChEMBL等の大量な公開データベースの一括検索を実現
2. 化合物を構造レベルで統合し、重複のない検索結果を出力
3. 自社ライブラリの統合や、公開データベースとの比較も容易
4. 多彩な検索条件による複合検索
5. 検索対象データが1億件を超えても低下しない、超高速な検索スピード
6. ユーザデータを取込み検索結果に反映可能なカスタマイズ性の高さ
7. 検索結果に対するクラスタリング解析等の高度な解析もサポート
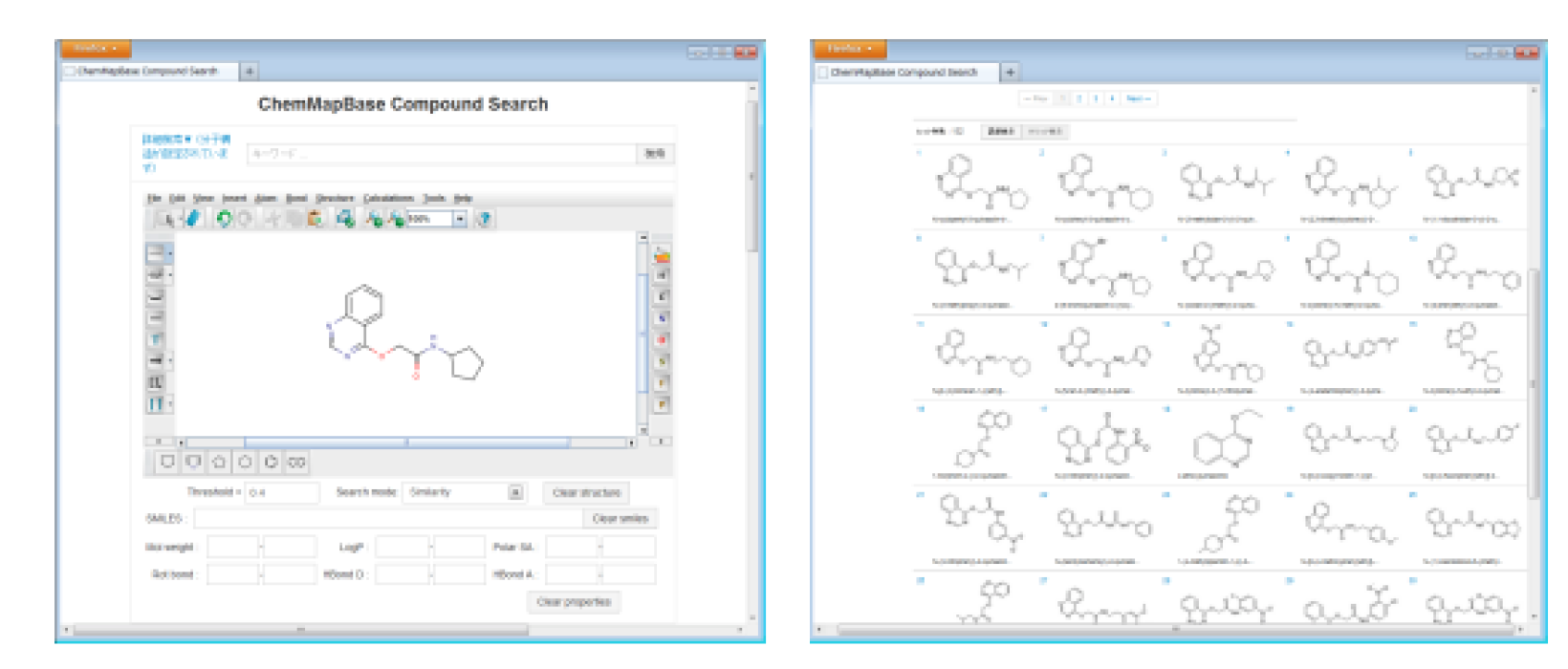
公開DB一括検索
PubChem、ChEMBL等の公開データベースへの一括検索が可能
網羅的に化合物検索を行う場合、通常は各公開DBの検索ページで別々に検索しますが、
ChemMapBaseでは、複数のデータソースを統合していますので、一括で検索結果を得ることができます。
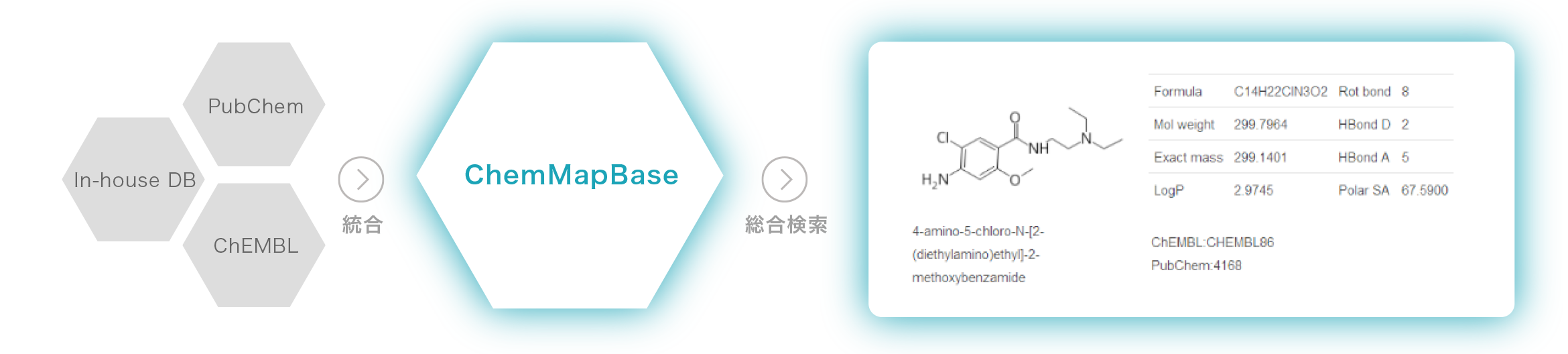
構造レベルでの統合
化合物を構造レベルで統合し、重複のない検索結果を出力
同じ化合物がDB間で(場合によってはDB内でも)、違う構造として表記されている場合(トートマー違い)がありますが、
ChemMapBaseではシステム側で構造レベルの統合を行っていますので、同じ化合物が同じレコードに集約された、
重複のない検索結果を得られます。ユーザによる重複排除の処理は必要ありません。
自社ライブラリの統合
自社ライブラリの統合や、公開データベースとの比較も容易
複数の公開DBの統合に加え、各企業が蓄積してきたユーザデータベースを統合して検索することができます。
この場合でも、構造レベルでデータ統合が行われますので、
ユーザが構造の書き方を気にする必要はありません。
また、化合物構造の分布がDB全体に渡って分かるため、手元の化合物ライブラリと公開DBのデータとの比較や、2種類の化合物ライブラリの比較なども簡単に実現可能です。化合物群の比較から、化合物群が持つ傾向を掴むことができます。

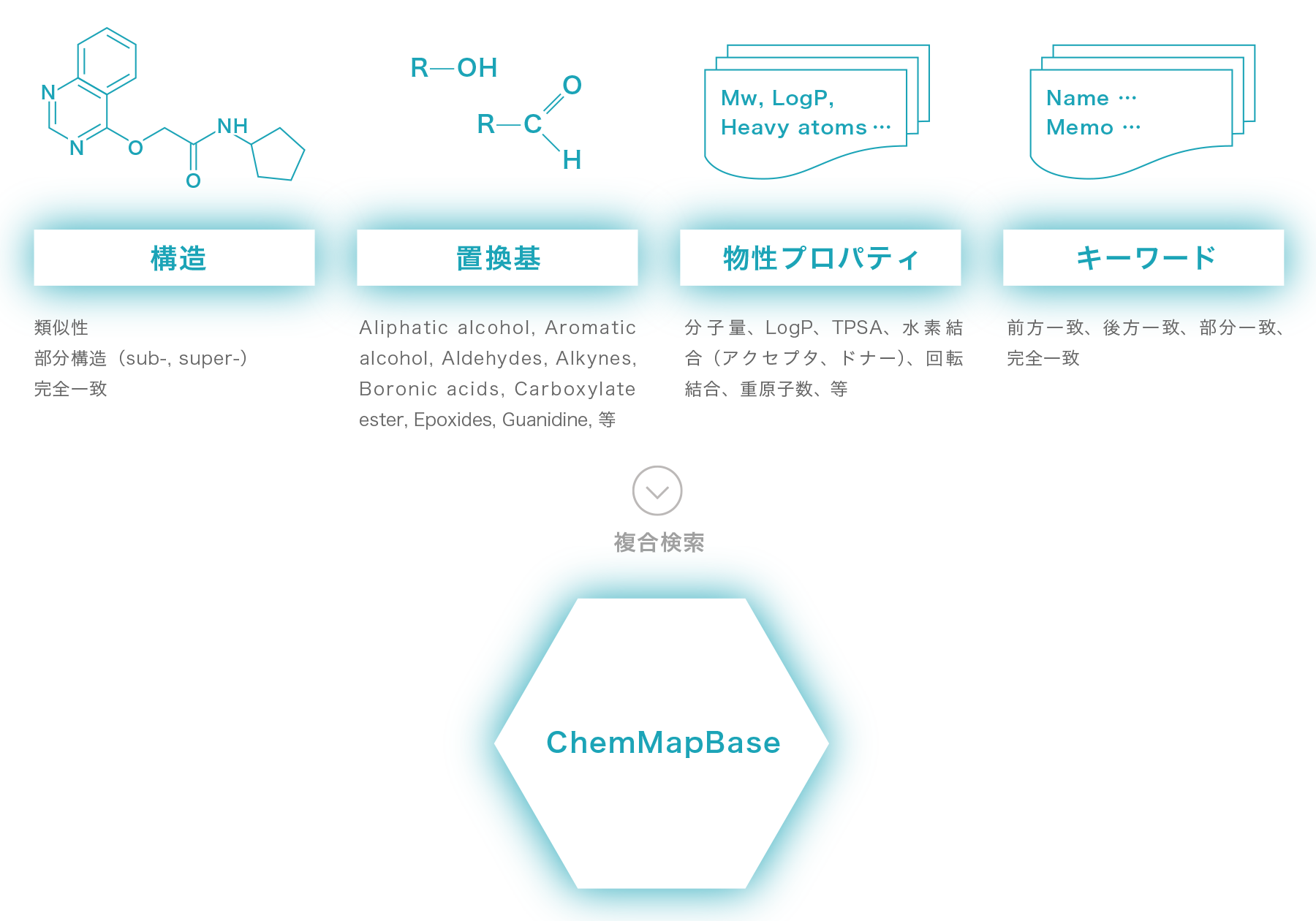
複合検索
多彩な検索条件による複合検索
構造による検索の他、プロパティ検索、全文検索等を組み合わせた複雑な検索クエリを実行することができます。
また、ユーザデータベースに関しては、プロパティやキーワードの追加が自由にできるため、
化合物の在庫量や購入履歴などの管理情報に対する、社内向けの特殊な検索クエリを構築することもできます。
超高速検索
検索対象データが1億件を超えても低下しない、超高速な検索スピード
独自の検索エンジンにより、非常に高速に検索します。例えば、PubChemのサイトで30秒以上かかるクエリも、数秒以内に結果を返します。
また、前述のような複合検索や、構造検索後にプロパティ検索を組み合わせることは、従来のやり方では検索速度が非常に遅く、実用的ではありません。ChemMapBaseでは、複雑な検索であっても、変わらない検索スピードで結果を出力します。
また、ChemMapBaseは、今後も増大するデータに対してスケールアウトが可能で、しかも検索スピードは高速なままです。
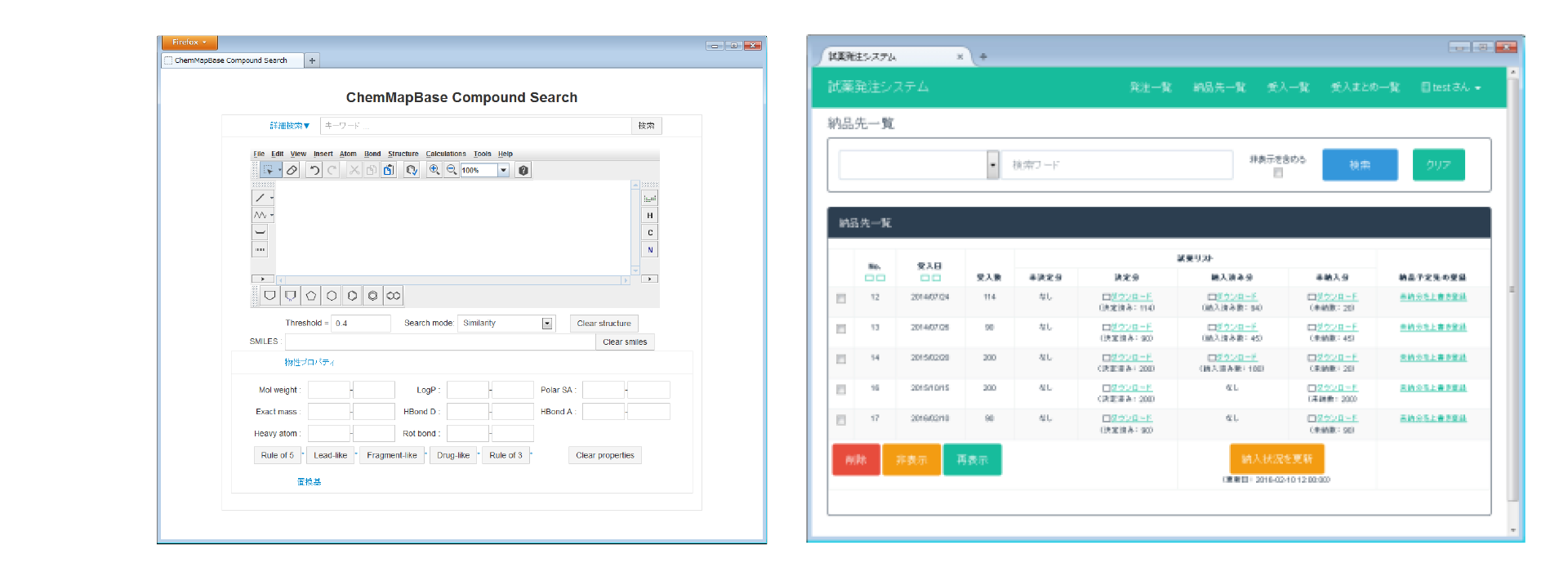
カスタマイズ性
ユーザデータを取込み検索結果に反映可能なカスタマイズ性の高さ
インターフェースは、ユーザの要望に合わせて容易にカスタマイズできるよう構造化されています。
化合物スケッチャーを変更したり、検索プロパティやキーワードを追加することはもちろん、
化合物の在庫量や管理者情報また活性データ等を連携させ、独自の検索フォームを作ることができます。
試薬の購入プロセスをスムーズに進められるなど、自社の業務プロセスに直接役立てることができます。
また、検索条件や検索結果を保存したり、検索結果同士をマージしたり差分をとるなど、さまざまな使い方に対応します
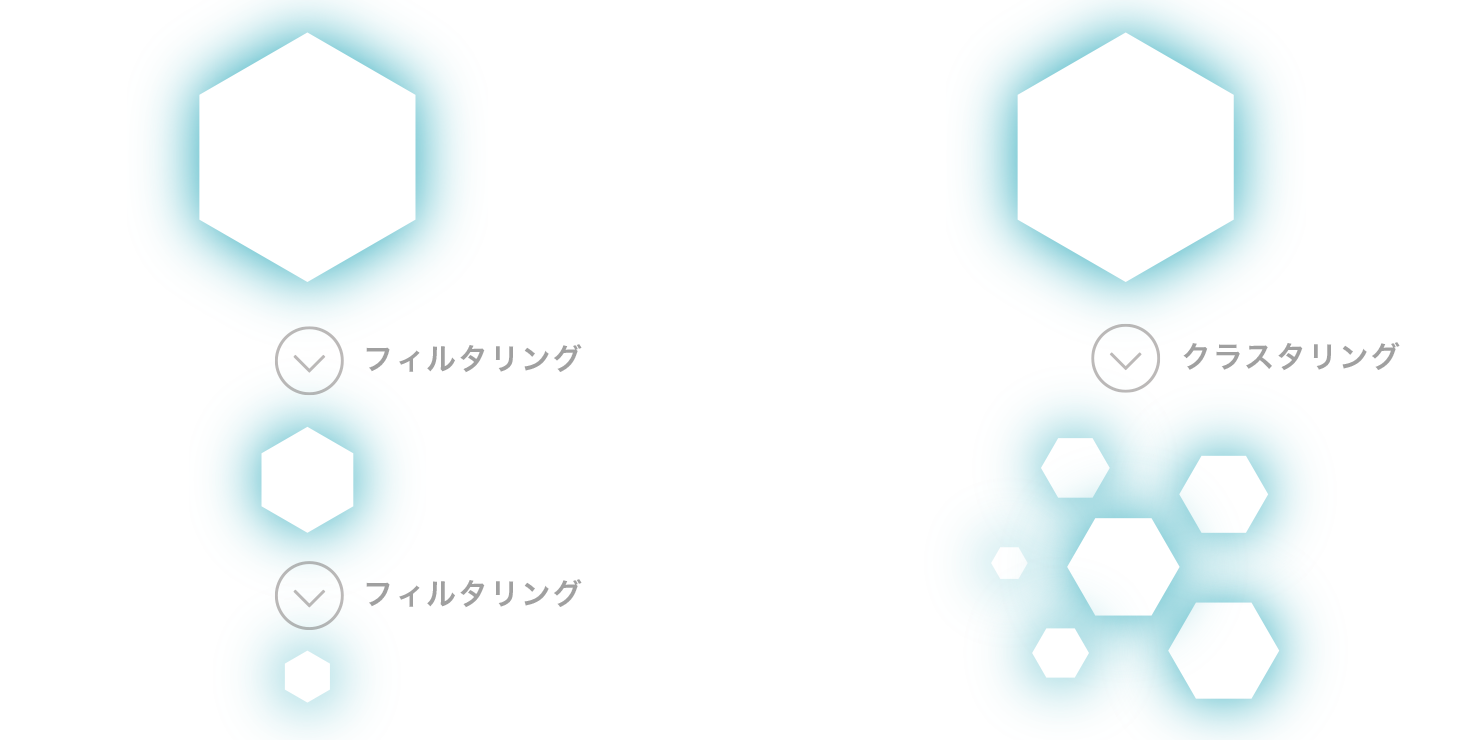
高度な解析
検索結果に対するクラスタリング解析等の高度な解析もサポート
検索結果全体に対して、絞り込みフィルタリングやクラスタリング解析を行うことが可能です。
絞込みフィルタリングでは、任意の項目に対して追加条件やキーワードを設定し、検索結果を自由に絞り込むことができます。
また、クラスタリング解析では、構造類似性などに基づいて類似化合物を1つのクラスタに集合させるクラスタリング解析が可能です。
単にデータベース検索を行うだけでなく、その後の解析をサポートすることで、化合物同定の高精度化に寄与します。
利用環境
オンプレミスでもクラウドでも、ユーザニーズに合わせて様々な環境でご利用いただくことができます。
詳細は、弊社までお問い合わせください。